
[read this post on Mr. Fox SQL blog]
Continuing on with my Partitioning post series, this is part 4.
The partitioning includes several major components of work (and can be linked below);
- partitioning large existing non-partitioned tables
- measuring performance impacts of partitioned aligned indexes
- measuring performance impacts of DML triggers for enforcing partitioned unique indexes
- rebuilding tables that are already partitioned (ie. apply a new partitioning scheme)
- implementing partial backups and restores (via leveraging partitions)
- implementing partition aware index optimisation procedures
- Calculating table partition sizes in advance
This blog post deals with rebuilding tables that are already partitioned (ie. apply a new partitioning scheme).
I will blog about the other steps later.
And so, lets get into the nitty gritty of the partitioning details!
Why Change an Existing Partitioned Table?
You may be wondering why you may ever want to rebuild a partitioned table to a new partition scheme, and you know, that’s a fair question. Depending on the size of your table it could be pretty expensive in regards to prep and execution time.
- Your partition scheme wasn’t extended in time and a significant amount of data is “bunching up” in the last partition, so much so that splitting the last partition is just as (or more) expensive than rebuilding. (I will blog later about why partition splits are so damn expensive!)
- You need to change the partitioning key
- You want to move the entire partition structure to new file groups/files
- You want to restructure the existing partitions to different ranges
- All of the above
So What Are My Options?
You have a few options to migrate the table across – and all of them will hurt!
- Rebuild the CLUSTERED index via DROP_EXISTING onto the new partition scheme – but this is a significant IO impact along with limitations such as the inability to change the partition key. (but your NC indexes will remain unaffected)
- Perform partition SPLITs – but you need to balance up the iterative costs/impacts with how many splits you need to do. If you also want to implement other changes, like data compression, or aligning existing non-aligned NC indexes, then this cannot be done via a SPLIT. (I will talk about these in a separate post)
- Rebuild the CLUSTERED index via DROP/CREATE onto the new partition scheme – which gives the option to change the key but depending upon your application is highly likely an outage! (and it will definitely rebuild your NC indexes)
- Unfortunately if you have a partitioned HEAP then there is no way to move the partitioning structure around, unless you create a clustered index on it.
Regardless you should always consider these WITH options during this work;
- ONLINE = ON allows you to build on a live system but it will take longer and potentially cause other impacts, such as greater tempdb usage.
- If you have a high performing tempdb then use SORT_IN_TEMPDB = ON, but beware how much space you need to sort the keys. You will need space approx equivalent to your largest index (which is probably the clustered one)
- If you haven’t compressed yet and you want to then now is a good option by adding DATA_COMPRESSION
- If you are doing this live and you don’t want to dominate the server, then use MAXDOP to prevent maxing out all of the cores on your machine
Lets create a partitioned play pen table, an aligned NC index, original and new partition function/scheme and then put some data in it. (We’ll use this table throughout this post to demonstrate how DROP_EXISTING works.)
Create Playpen Table, Partition Function/Scheme and Load Data
--Partition Function ORIGINAL
CREATE PARTITION FUNCTION pf_myorders_original (int) AS RANGE RIGHT FOR VALUES(0, 10000, 20000, 30000, 40000, 50000)
GO
-- Partition Scheme ORIGINAL
CREATE PARTITION SCHEME ps_myorders_original AS PARTITION pf_myorders_original ALL TO ([PRIMARY])
GO
--Partition Function EXPANDED
CREATE PARTITION FUNCTION pf_myorders_new (int) AS RANGE RIGHT FOR VALUES(0, 10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000, 100000)
GO
-- Partition Scheme EXPANDED
CREATE PARTITION SCHEME ps_myorders_new AS PARTITION pf_myorders_new ALL TO ([PRIMARY])
GO
--Partitioned table
CREATE TABLE dbo.myorders
(
myorder_id INT NOT NULL
, myorder_key INT NOT NULL
, myorder_date DATETIME NOT NULL
, myorder_amt MONEY NOT NULL
, myorder_details NVARCHAR(4000) DEFAULT '' NULL
, CONSTRAINT pk_myorderid PRIMARY KEY CLUSTERED (myorder_id ASC)
WITH (DATA_COMPRESSION = NONE)
ON ps_myorders_original(myorder_id)
)
GO
--Partition aligned NC index
create unique nonclustered index uk_myorderid
on dbo.myorders(myorder_key, myorder_id)
GO
--Load Data
begin
INSERT INTO dbo.myorders
SELECT
TOP 87500
ROW_NUMBER() OVER (ORDER BY o1.object_id) - 1
, CAST((ROW_NUMBER() OVER (ORDER BY o3.object_id) * RAND(1) * 2) AS INT)
, DATEADD(hh, (ROW_NUMBER() OVER (ORDER BY o1.object_id)) / 3, '2013-01-01')
, RAND(ROW_NUMBER() OVER (ORDER BY o3.object_id)) * RAND(ROW_NUMBER() OVER (ORDER BY o3.object_id)) * 730
, REPLICATE('X', RAND(o3.object_id) * 1000)
FROM master.sys.objects o1
CROSS JOIN master.sys.objects o2
CROSS JOIN master.sys.objects o3
ORDER BY 1
end
GO
So What Does Our Table Structure Look Like?
You can use this handy query to check the partition structures;
SELECT s.NAME AS 'schema' , o.NAME AS 'table' , CASE o.type WHEN 'v' THEN 'View' WHEN 'u' THEN 'Table' ELSE o.type END AS objecttype , i.NAME AS indexname , i.type_desc , p.data_compression_desc , ds.type_desc AS DataSpaceTypeDesc , p.partition_number , pf.NAME AS pf_name , ps.NAME AS ps_name , CASE WHEN partitionds.NAME IS NULL THEN ds.NAME ELSE partitionds.NAME END AS partition_fg , i.is_primary_key , i.is_unique , p.rows FROM sys.indexes i INNER JOIN sys.objects o ON o.object_id = i.object_id INNER JOIN sys.data_spaces ds ON DS.data_space_id = i.data_space_id LEFT JOIN sys.schemas s ON o.schema_id = s.schema_id LEFT JOIN sys.partitions p ON i.index_id = p.index_id AND i.object_id = p.object_id LEFT JOIN sys.destination_data_spaces dds ON i.data_space_id = dds.partition_scheme_id AND p.partition_number = dds.destination_id LEFT JOIN sys.data_spaces partitionds ON dds.data_space_id = partitionds.data_space_id LEFT JOIN sys.partition_schemes AS ps ON dds.partition_scheme_id = ps.data_space_id LEFT JOIN sys.partition_functions AS pf ON ps.function_id = pf.function_id WHERE o.NAME = 'myorders' ORDER BY s.NAME , o.NAME , i.NAME , p.partition_number GO
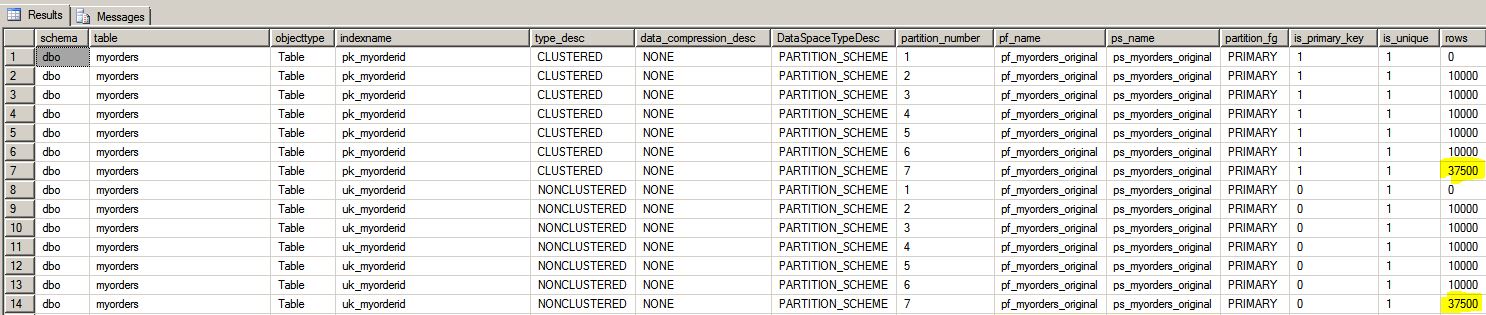
A couple of key points with a pre-partitioned position;
- The above table hasn’t had the partition function expanded in time and so 37,500 rows are bundled into partition 7 at the end.
- The table and NC index is partitioned on ps_myorders_original(myorder_id) all to the [PRIMARY] FILEGROUP
- The table and the NC index share the same partition function/scheme. If you SPLIT a partition function/scheme then ALL objects on that function/scheme are affected in the same statement.
Now lets repartition this partitioned puppy!
Rebuild the Table with DROP_EXISTING
Lets rebuild the clustered index using DROP_EXISTING to my new partition function ps_myorders_new and see what happens.
CREATE UNIQUE CLUSTERED INDEX pk_myorderid ON dbo.myorders (myorder_id) WITH ( DROP_EXISTING = ON, SORT_IN_TEMPDB = ON, ONLINE = ON, MAXDOP = 0 ) ON ps_myorders_new(myorder_id) GO
Table 'myorders'. Scan count 28, logical reads 151453, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table '635149308'. Scan count 0, logical reads 49458, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
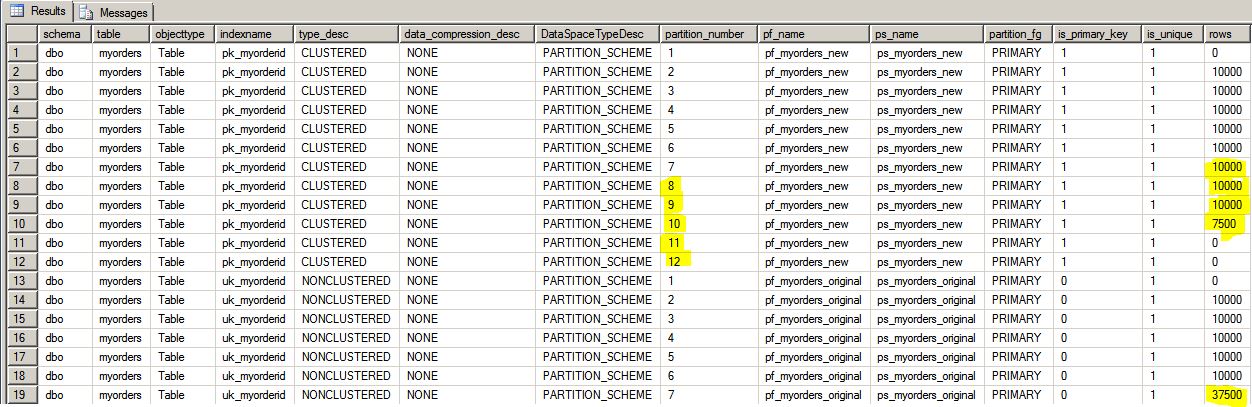

So what happened?
- Using ONLINE=ON and SORT_IN_TEMPDB = ON created temporary table “635149308” for key sorting in tempdb. This required 200,911 logical reads.
- If using ONLINE=OFF then only 16,387 logical reads are needed (in total), a saving of over 92%!
- The clustered index was completely redistributed across the new partition function with the previously “bunched up” rows now spread across the partitions, and leaving a number of empty partitions at the end. (Which is a partitioning best practice!)
- It rebuilt JUST the clustered index to the new partition scheme – the NC index was completely UNCHANGED and remains on the original partition scheme!
- Changing the partition structure does not change the partitioning key and therefore the NC indexes do not need to be rebuilt.
- Whats interesting is that if this table was NOT partitioned then the NC indexes WOULD have to be rebuilt when applying a partitioning scheme! Go figure?
And So, What are my Final Options?
Think about what you want to get out of the effort, if you need to move the table anywhere other than where it is now then using this method is good as your new partition scheme can target completely new filegroups / files. Beware though that NC indexes wont move with the table and you need to do that separately!
If you are prepared to wear a massive jump in logical reads vs the benefits of doing the work ONLINE then that is a probably the best option.
Long short, you need to test it yourself on your table and your data as your mileage may vary.
Disclaimer: all content on Mr. Fox SQL blog is subject to the disclaimer found here


CREATE UNIQUE CLUSTERED INDEX pk_myorderid
ON dbo.myorders (myorder_id)
WITH
(
DROP_EXISTING = ON,
SORT_IN_TEMPDB = ON,
ONLINE = ON,
MAXDOP = 0
)
ON ps_myorders_new(myorder_id)
GO
What if partition key changes to some column which is not included in primary key??
LikeLike
Always best to test it… and so tried to change the PK during the rebuild to another int data type field “myorder_key” thats already in the table – and when trying this essentially you’ll get an error “Column ‘myorder_key’ is partitioning column of the index ‘pk_myorderid’. Partition columns for a unique index must be a subset of the index key.”
So What does this mean? Well it means that you would need to include the partitioning coloumn in the index.
LikeLike